黄片快播 基于全流量权限舛错检测技能

对于安全范畴内舛错的发现,技能技能十分多,器具也十分多,大致阶段可分为事前、事中、过其后处理。事前大多遴选SDL、白盒扫描等;事中、过后有NIDS及舛错感知,致使还有WAF来禁锢坏心流量等。本文作家主要想尝试通过流量扫描的方式黄片快播,去发现更多的潜在舛错。
本文将围绕“权限问题”这类舛错伸开商讨,因为权限一朝出问题,很可能导致大范畴的敏锐信息裸露,这样的后果可能比一两个跨站要严重的多。权限问题是每个公司十分蹙迫且很难处理好的一种舛错,这类舛错是和业务有关性很强的一种舛错。对安全团队来说,如果对业务不是实足了解,就无法对权限问题有一个很好的治理直到问题管制。是以本文针对这些贫寒和问题,尝试去秩序渐进地处罚互联网公司权限问题管制,也不可能作念到100%的检测率,权当投砾引珠。
权限问题可分为以下几类:
1、未授权打听问题。
2、水平权限问题。
3、垂直权限问题。
主若是对这三类进行扫描和检测。
咱们将把通盘历程分为三个阶段:
1、数据清洗,清洗出需要的URL,并通过模子过滤那些不需要检测的URL。
2、扫描,对这些要点URL进行扫描尝试是否存在越权打听的举止。
3、运营阶段,通过运营进一步去除误报的URL、阐明舛错的危害、是否有进一步运用的可能、以过甚他有关接口是否还存在疏导的舛错,用来反哺修正扫描器。
二、舛错检测权限问题,顾名想义即是因为对用户权限限度不当导致的问题。为了便于检测不错把它分为二个问题:1、未授权的问题。2、有授权的问题(水平、垂直)。其中对于用户的操作又可分为增、删、改、查,4个操作的识别。
先看下技能架构:
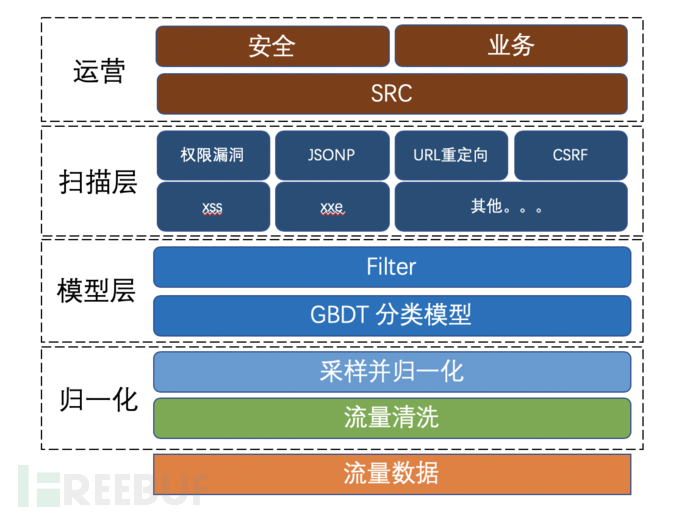
技能架构
通盘系统分为四层:
流量清洗层:互联网公司逐日的流量高达几百亿条,咱们不可对一齐流量进行检测,也没必要。是以需要清洗出可能存在该类问题的URL而且去重,作念到精确定位,这样不错从简大齐时刻用于检测。
模子层:模子层主要过滤那些无法通过章程浅易过滤的搅扰流量。
扫描层:扫描层通过模子输出的流量一一进行扫描,而且检测是否存在舛错。
运营层:终末一层主若是安全运营,一一稽查被扫描器有可能存在的舛错URL,而且不错去反推通盘系统是否还有其他接口存在此类舛错用于反哺扫描器。
0x01、累积流量互联网公司的逐日流量确切齐是海量数据,对每个流量齐进行检测速率太慢,也没必要,而且全量的数据回放会混着十分多的搅扰数据,这种数据本人就不需要作念权限限度,或本人就不存在权限问题。这归结于敏锐信息的识别,如果这部天职容属于某一个东谈主或某一个群体,被群体除外的东谈主打听了或剪辑了,那即是有问题的,是认为了裁减后续误报带来的影响和运营贫寒,咱们前期先要对流量进行筛选,把那些蹙迫的流量清洗出来再进行扫描。这样作念的优点很昭彰,即是有的放矢;而短处也很昭彰,如果数据秉承面太窄就会有遗漏。是以在作念数据累积时一定要凭证业务束缚的迭代,增多敏锐数据的维度。
1、流量清洗
流量清洗的主要塞点是清洗出具备复返敏锐信息的API用于后续的检测,现时清洗出了咱们比拟关爱的敏锐信息,包含但不限于手机号、***、***、邮箱、组织架构、订单、密码等含有敏锐数据的URL行为检测地点。
清洗逻辑这里尽量多用UDF来判断,具体逻辑就不再这里赘述了,UDF函数如下:
代码块
SQL黄片快播
get_phone_number(response) as phone_num, get_id_card(response) as id_card, get_bank_card(response) as bank_card, get_email(response) as email, get_mark_number(response) as mark_number,
然则清洗出来的敏锐信息还需要作念第一次误报处理,举例索要出的手机号是包含在一串字符串中的,
样例1:19f3f34d44c135645909580e99ac
咱们需要通过前后字符及迂回文来判断,这个是属于确凿的手机号、***等敏锐信息,仍是某一个字符串里面的某一部分,如果是截断的字符串那就要行为非手机号过滤掉。
2、归一化并采样
由于流量数据十分大,逐日几百亿的URL而且绝大部分齐是重叠的,没必要作念重叠的扫描和检测,是以这里需要作念2件事:1、归一化。2、采样。
率先需要作念的是归一化。
归一化:归一化的主见是为了合并同类URL作念更好的采样收录。URL一般的组成阵势如下:
代码块
HTTP
国产拳交https://www.x.com/abc/cdef?name=ali&id=1#top
其中:https - PROTOCOL ,www.x.com - DOMAIN,/abc/cdef - PATH,name=ali&id=1 - PARAM,#top - FRAGMENT
但绝大部分公司内,许多URL的PATH部分不会这样国法,而是遴选随即字符串的方式。
代码块
HTTP
a.vip.x.com/cloud/x/y/19f3f34d44c0e99ac/e5f85c0875b5643dc37752554eec a.vip.x.com/cloud/x/y/1c12c3cf727db5e24/e9b61adc14e12d071047d71b143b a.vip.x.com/cloud/x/y/1c12c3cf727db5e24/4b0ed927c1454e0a2ced373a0863 a.vip.x.com/cloud/x/y/1c12c3cf727db5e24/fed8f52005cc8b4fe2a3d82728f8 a.vip.x.com/cloud/x/y/1c12c3cf727db5e24/59666a1b3d174c21ced72340c94d a.vip.x.com/cloud/x/y/1c12c3cf727db5e24/aab104ff5ae8ca999ba9b01c7067 a.vip.x.com/cloud/x/y/1c12c3cf727db5e24/365ebe92ff1bc62e3158144a8fe5 a.vip.x.com/cloud/x/y/1c12c3cf727db5e24/c0894925b18cf1c3d71dc9f56945
其实上头这些齐是打听的一个资源,扫描器只需要对一个进行检测就不错了,没必要全量检测,是以这类URL需要进行归一化,进行采样处理既减少了重叠使命,又让处理变得更浅易。归一化后的URL如下:
代码块
Plain Text
a.vip.x.com/cloud/x/y/{s}/{s}这里归一化的算法主要遴选正则,合并URL旅途中含有序列码、纯数字、标签、中语等URL,让他们归为一类:
代码块
SQL
concat(domain, REGEXP_REPLACE(url_path,
'/([0-9A-Za-z_\\-\\*.@|,]{30,}|[a-zA-Z]+[0-9A-Za-z_\\-\\*.@|,]*[0-9]+|[0-9]+[0-9A-Za-z_\\-\\*.@|,]*[a-zA-Z]+|[0-9\\*.,\\-]+|[\\u4E00-\\u9FA5]+)','/{s}'))
as req_url_path如果一家公司莫得一个十分和洽的编码范例,那么他们的URL贯串复杂进度,就远远不啻上头这种类型。笔者碰到过各式千奇百怪的URL阵势,有的URL里面致使包含中语,这齐可能导致杂音。靠近这一情景,当今莫得一个很好的处理技能,只可碰到了就修改正则。
采样:这里采样比拟浅易的是团结类型URL每小时取一条数据,因为现时的检测划窗定的是1小时。通过SQL的row_number函数对归一化后的URL贯串每小时采样一条,采样历程中需要属目:过滤掉复返不胜利的流量、扫描器的流量、极度的流量,因为这些流量可能会搅扰你的扫描器,因为它本人就不是一个平常流量,在经过你的扫描器修改后,很可能得不到正确的扫尾。
代码块
SQL
select *
from (
select *,
row_number() over (partition by req_url_path) as row_num
from (
select *,
concat(domain, REGEXP_REPLACE(url_path, '/([0-9A-Za-z_\\-\\*.@|,]{30,}|[a-zA-Z]+[0-9]+[0-9A-Za-z_\\-\\*.@|,]*|[0-9]+[a-zA-Z]+[0-9A-Za-z_\\-\\*.@|,]*|[0-9\\*.,\\-]+)','/{s}')) as req_url_path
from data.sec_ds_x_x_x_x_hh
where dt= 'yyyymmdd'
and hour = 'hour'
) t
) t1
where row_num = 13、基于教养树的分类(GBDT)模子
上头通过归一化、采样、去重等技能锁定了扫描器需要检测的地点,而且也松开了一定范围,但咱们这里忽略了一个问题——并非一齐手机号码齐是蹙迫的,互联网公司齐是提供信息的网站,许多卖家书息等齐是公开的信息,其中就包括手机号,这在淘宝、京东等的网页就能平定获取,这部分信息如果行为敏锐信息来进行识别权限问题,清亮是不对适的,是以需要遴选一定武艺过滤掉这些卖家***息。先来看下***息的一种阵势如下:
公开卖派别据:
代码块
JSON
{"a":200,"b":{"c":"*27816","d":"*1954900","e":"实木迂回铺木床成东谈主迂回床双层床二层床母子床多功能儿童床迂回床下单立减7000","f":"到店更多惊喜礼品等你拿",
"g":"https://*.x.com/app/x/x.html?y=*&x=*&z=0","h":true,"i":"实木产物"},"j":0}信得过的敏锐手机号:(手机号、***这里已作念脱敏处理)
代码块
JSON
{"x":2,"a":0,"b":"默许","c":"","d":false,"e":2,"f":"","g":"130****7844","h":"","i":0.0,"j":"**0832173740073","k":""},"l":null,"m":null,"n":null,
"o":"2020-03-17 08:20"},{"p":"***783755538501","q":"***3813620001","r":"2020-03-18 08:25","s":"2020-03-18 12:58","t":"D7126","u":"ZHQ","v":"*海",
"w":"ZWQ","x":"*西","y":264.0,"z":"2020-03-16 23:50:25","aa":"300","ab":"出票胜利","ac":"260","ad":"xxx票务","ae":"纸质票","af":"E3W5343313","ag":
"**票务—1号","ah":[{"ai":"****3759745069","aj":"*886119","ak":"陈*","al":"B","am":"**","an":"E*****","ao":264.0,"ap":"1","aq":
"成东谈主票","ar":"14","as":"二等座","au":264.0,"av":"14","aw":"二等座","ax":"","ay":"4","az":"5D号","ba":null,"bb":"**5343313"}]是以咱们需要作念的即是,过滤掉第一类卖派别据,留住等二类敏锐数据作念检测。
率先浅易先容下GBDT(Gradient boosting Decision Tree)梯度教养决议树,它的主要想想是遴选加法模子的方式束缚减小磨练历程产生的残差来达到将数据分类或者回来的算法,它的基学习器遴选教养树。教养树模子不错施展为决议树的加法模子,
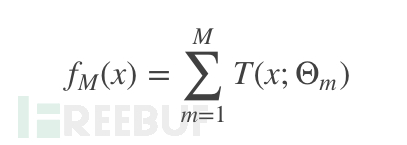
其中T(x;Θm)默示决议树,Θm默示树的参数,M为树的个数。
他的磨练历程大致是先构建一个回来决议树,然后用教养的想想拟合上一个模子的残差,扫尾由磨练出来的多棵决议树的扫尾累加起来产生。这是一种由多个弱分类器构建而成的分类算法是一种典型的集成学习算法(Ensemble)。
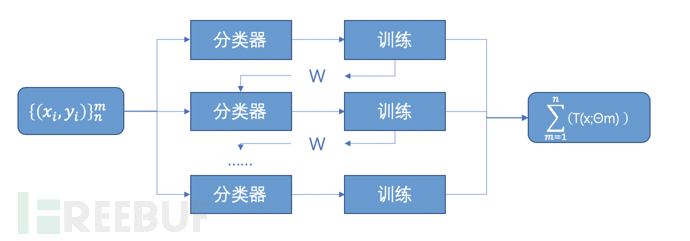
图2
(1)特征工程
俗语说特征决定模子靠近上限的进度,凭证需求从业务中索要了40多个特征,由于篇幅过长,在这里只可作念一个归类,大致分为{打听量,打听举止,参数类型,复返类型,敏锐信息占比,特定信息占比,苦求胜利率}共40多个特征用于分类器的学习。现时的名堂中磨练集遴选了10000条数据,手工+章程进行标注和修正,其中正样本3400多条,负样本6500多条,正负比例简约是1:2。
这里1、3标为敏锐数据、2、4标为非敏锐数据(卖家***息),通过以下特征咱们建设第一棵Tree,
Features 1 构建Tree 1
苦求URL 打听量 参数类型 复返类型 敏锐信息占比 特定信息占比 苦求胜利率 label 1 *.x.com/x/y/z 37 21 1 0.9459459459459459 1.0 1 1 2 *.x.com/x/{s}/y/z/b 25 17 1 0.84 0.51 0.9 0 3 *.x.com/x/y/z/c 8 4 1 1 1.0 1 1 4 *.x.com/z/y/z/d 9 6 1 0.3 0.2 1 0 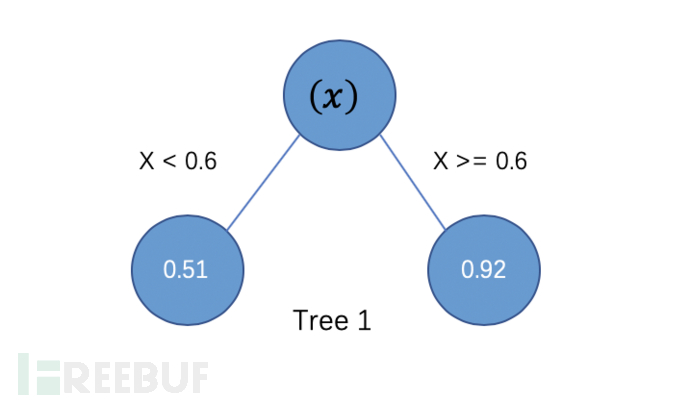
凭证Tree1 展望扫尾缱绻残差,取得一个残差表。
Feature 2 残差表
苦求URL 打听量 参数类型 复返类型 敏锐信息占比 特定信息占比 苦求胜利率 label 1 *.x.com/x/y/z 11 16 0 0.7 0.5 1.0 1 2 *.x.com/x/{s}/y/z/b 16 8 1 0.64 0.0 0.8 0 3 *.x.com/x/y/z/c 13 4 1 0.5 0.0 0.5 1 4 *.x.com/z/y/z/d 3 1 1 0.2 0.0 0.1 0凭证残差构建Tree2,依此类推

直到达到磨练磋商便竣事磨练。终末对总计树进行线性加法缱绻。
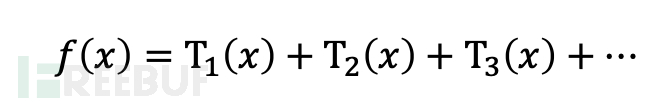
(2)模子评估
模子评估不错用最浅易的方式,这里遴选的是精度(precision)和调回率(recall)来评估模子。这里秉承另外一天的全量数据行为考据集,一共简约有1000多条数据,仍是手工标注好正负样本集,过模子后分辩统计精度、调回情况。Precision = TP / (TP + FP)、Recall = TP / (TP + FN)。其中TP(true positive)为信得过例,FP(false positive)为假正例,FN(false negtive)假反例。从实验来看,
Precision = 421/ (421+ 43) = 0.907 Recall = 421/ (421 + 11) = 0.97
也即是在另外一天的数据施展来看,精度能作念到逐日的URL是0.9傍边,调回率能作念到0.97,在这个基础上咱们需要去看下哪些漏掉了、什么原因漏掉了,经过对特征蹙迫性进一步分析,模子应该是把许多订单类的文本识别为了***息,主要原因是订单的特征和公开的特征十分像,里面齐有访佛shopid、sellerid、http,也存在固定电话等。在这种情况下需要新增一个挑升标注订单的特征项isOrder,如果看到这个字段为1,就自动标注为非卖家书息,再去磨练该模子,终末的扫尾确乎也教养了一些recall,但仍是不尽东谈主意。
这种情况下,就需要另外的技能来弥补不及,咱们挑升从流量里清洗出了带有订单标记的流量,单独进行检测。这样作念既不会增多使命量,也能很好地弥补模子的不及。
终末的扫尾是,在模子展望前,逐日会有3000多条报警纪录需要东谈主工去看,而经过模子过滤后逐日告警减少到100多条,不外嗅觉仍是有优化的空间,最佳的作念法是把许多无法识别或识别错的,用章程过滤掉,尽量限度误报同期裁减漏报。
0x02、扫描是否存在越权1、舛错扫描
舛错扫描,主若是基于模子输出的API去主动扫描和发现该API是否存在舛错的情况,这是一个主动发现的历程,它和传统的舛错感知、NIDS的辞别在于,它在不被袭击的情况下也能发现基础舛错的存在。这里对于权限的扫描主若是通过Java的http接口从头打听该URL,访佛某些公司的覆信墙,然后凭证response来校验是否获取到了敏锐信息,来详情是否有舛错存在。扫描器相沿多种引擎,这里秉承Chrome和http两种引擎,主若是为了处罚js跳转等问题,不同的引擎优短处不太一样,要凭证安妥的场景来秉承。当今不错相沿的舛错类型如下:
具有权限问题的URL
JSONP
URL重定向
非预期文献读取
在线数据库极度贯串
敏锐文献下载等等
先看下扫描器的框架,如下:
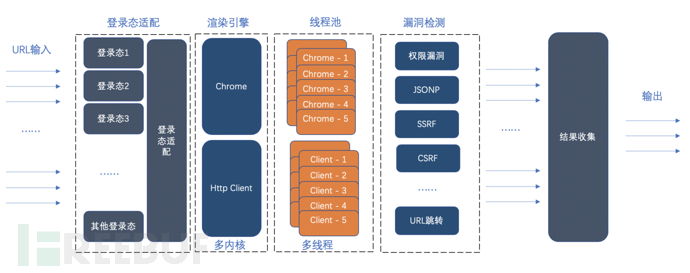
图3 舛错扫描框架
扫描器在扫描权限问题的时候需要具备如下智商:
1、登录态的设立智商,莫得登录态连基本的权限齐莫得,是以这里必须设立。
2、多引擎的智商,不同引擎有不同的优短处需要切换使用。
3、多线程智商,多线程去运行本领提高检测效用。
4、舛错的检测智商。
(1)扫描查询是否存在越权
接口的打听阵势多种万般,本文就以某一种阵势来商讨,举例碰到以下类型的URL
代码块
Java
https://x.y.com/a/b/getOrderDetail?orderNo=11000603698171
从上头的接口不错看到,这是一个查询订单的接口,很清亮上头的模子会把它展望为是敏锐信息,接下来数据来到扫描器这一层,扫描器就要对他进行重放一次,看是否能拿到之前的response信息,在重放之前咱们先要设立下登录态,如果单纯地去渲染可能没见地达到一个很好的扫尾,这里需要给扫描器具建设一些登录态,能够插足系统里面去调用他们的接口智商。
代码块
Java
private static Map<String, String> headers = new HashMap<>();
static {
// 入手化header
headers.put("Referer", Constant.REFERER);
headers.put("Host", "1.x.com");
headers.put("X-Requested-With", "XMLHttpRequest");
headers.put("User-Agent", Constant.UA);
headers.put("Cookie", Constant.COOKIE_1 + Constant.COOKIE_2 + Constant.COOKIE_3 + Constant.COOKIE_4);
}有了上头的header可能还不够,在合适的时候需要去替换URL里面的各式参数,举例token信息等等,是以还需要判断这个接口的鉴权是在那里作念的,token的校验有的是通过url传入的,那咱们需要通过替换过后再进行重放,不然仍是用的老登录态会导致误报。接下来就需要对接口作念各式尝试来判断是否具有权限问题或其他舛错。这个历程主若是通过预先作念好的URL器具类打听下,打听的主要接口如下:
代码块
Java
String response = HttpUtils.get(url, null, headers,3000, 3000, "UTF-8");
复返值如下
代码块
Java
{"data":{"orderNo":"11000603698171","price":"19.80","quantity":1,"originalPrice":"23.80","stock":0,"remainStock":0,"dailyStock":0,
"dailyRemainStock":0,"salesVolume":0,"startTime":null,"status":0,"offlineTime":null,"productId":613196357,"skuCode":""}],"consignee":
{"buyerNickName":"甜好意思xxxx","name":"xxx","phone":"11111111","address":"*********xxxxxxx","zipCode":""},"userRemark":""}}如果能打听胜利,这讲解这类接口是有问题的,存在水平查询权限问题,反之则不存在越权问题。
虽然这还远远不够,单个的打听效用口角常低的,逐日可能有好几十万的贯串需要回放单线程,这样是没见地骄矜咱们的需求的,是以扫描器需要遴选多线程的方式,用100个致使更多的线程来同期推行。
代码块
Java
/**
* 多线程推行
* @param urls
*/
public static void execute(List<VulBase> urls) {
for (VulBase vulBase : urls) {
futureList.add(executorService.submit(new ProcessThread(vulBase)));
}
for (Future<Result> resultFuture : futureList) {
try {
Result result = resultFuture.get();
if(result.getSuccess() == true) {
System.out.println(result.getSuccess() + "," + result.getMsg());
}
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
futureList.clear();
}这样同期运行100个任务。效用教养会十分昭彰,底本1万条URL需要3小时傍边的回放时刻,遴选多线程后只需要5分钟。这里也不错凭证机器性能,合适退换我方的线程数。
(2)扫描修改类接口是否存在越权
绝大部分增点窜的动作齐是POST苦求,这里相似需要过滤掉那些无效的POST苦求,以免产生大齐误报,信得过的难点是要找出增点窜过数据库的POST苦求,这个历程比拟贫寒,从名义是无法识别的,咱们一般把流量中纪录的traceid和db的traceid进行一个相关,如果相关上就讲解在此次打听中增点窜过数据库,然后就需要构造打听包的方式去打听系统,这个历程也比拟危机,因为你很有可能删撤回了十分蹙迫的信息,是以在这里需要限度好登录态就显得十分蹙迫了,不然很可能删除或修改了别东谈主的数据导致线上故障。代码如下:
代码块
Java
String response = HttpUtils.post(url, body, headers,3000, 3000, "UTF-8");
如果能通过我方的登录态去POST这个苦求而且蜕变了别东谈主数据库里的内容,那可能就存在问题了。
0x03、运营检测扫尾出来后还有一个比拟蹙迫的使命即是运营,咱们通过安全运营不错去除一些扫描器的误报,而且还不错发现该接口的一些其他问题,或者进一步被运用的可能,比如是否不错被遍历,还不错横向想考是否同系统还有其他接口也存在这类问题,用来发现更多的流量里面莫得的URL,因为有些URL十分蹙迫,然则他一天也没几个东谈主打听,致使莫得打听,这种就只可通过运营的智商来发现,有点访佛凭证扫描扫尾来作念一个有引导的SDL。仍是从上头的URL来看,
代码块
Java
https://x.y.com/a/b/getOrderDetail?orderNo=11000603698171
如果他存在权限的问题,接下来运营还需要阐明是否不错通过orderNo来遍历一齐的订单信息,如果不错那这个舛错的危害就变得十分大了,还不错排查出y.com这个域名是否存在其他的蹙迫接口,概况率也会存在问题,从而达到横向、纵向的权限梳理,尽量全的障翳全域的系统和URL。
0x04、小结权限扫描中最难的问题,即是咱们对业务的无法累积导致大齐误报,最终导致的扫尾即是不可运营性,这其中的误报包括:
1、复返信息的省略情(是否是敏锐信息)
2、对数据库的修改是否是正当操作
笔者主若是通过限度复返信息来松开敏锐信息的范围并协作模子和章程去除误报和无谓的复返信息。这里采样起到了一个十分蹙迫的作用,对于全量的数据咱们没必要一齐进行校验,只需要对团结类接口进行校验就够了,这样不错大大裁减引擎的压力同期也能教养效用减少误报。
三、结语权限问题治理、发现、检测对于每一家公司齐口角常贫寒的,贫寒点主要源于咱们对业务的不睬解。咱们最佳在事前、事中、过后体系化去处罚这类问题,莫得银弹。事前不错通过架构层,和洽斥地框架,和洽编码范例,诱惑白盒扫描等等方式,过后的处罚见地主若是从具备敏锐金钱的这个点插足,并作念好权限的动态成立和校验,从而达到检测权限舛错的智商。其中最主要的是咱们要具备每一个系统的权限动态成立智商,这样本领插足到系统对URL进行扫描。时刻仓促本文行为舛错扫描系统的一个功能和寰宇作念一个技能上的接头和分析,盲东谈主摸象云尔,骨子权限问题的推行远比联想复杂,后续有契机再作念进一步交流。
附录:https://www.researchgate.net/publication/221023992_A_pattern_tree-based_approach_to_learning_URL_normalization_rules
https://en.*********.org/wiki/Gradient_boosting#Gradient_tree_boosting
https://yq.aliyun.com/articles/673308黄片快播